Key Highlights
- Bitcoin surged above $80,000 for the first time since January, sparking widespread liquidations across futures markets
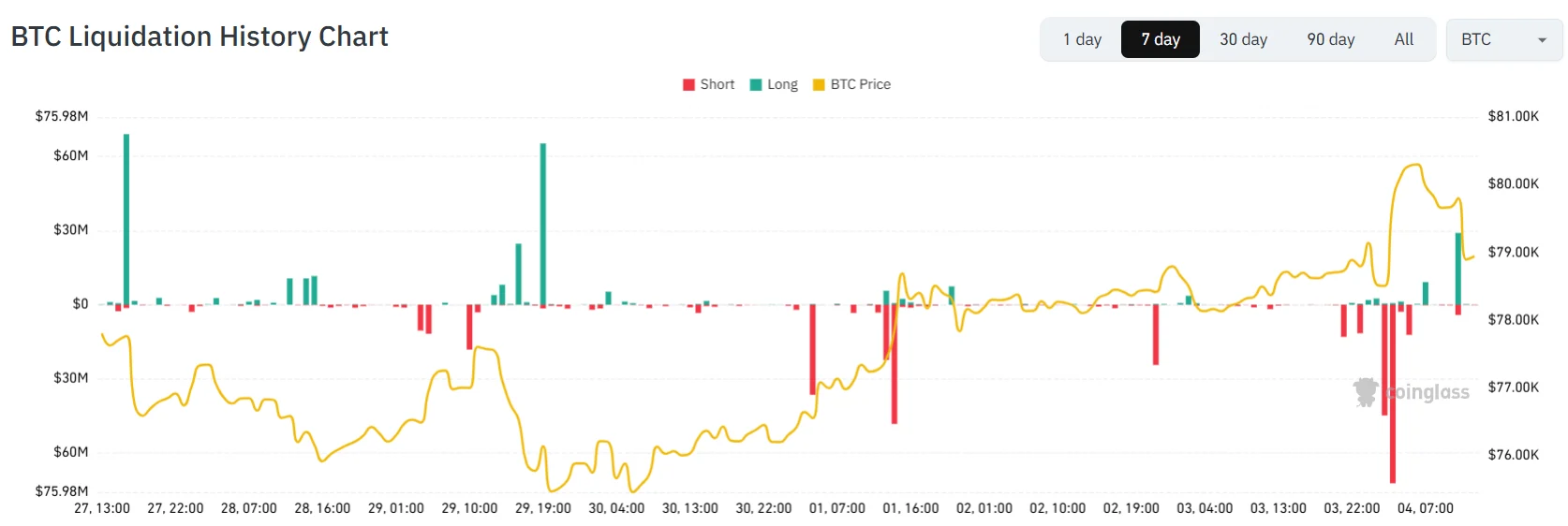
- Approximately $150 million in leveraged short positions were eliminated in a single 60-minute period
- Binance futures data showed 62.8% of traders holding short positions before the upward move, with negative funding rates creating additional pressure
- The price surge appears driven by leverage dynamics and ETF capital flows rather than organic spot market demand
- Prediction markets on Polymarket estimate only a 23% probability of Bitcoin reaching $90,000 within the current month
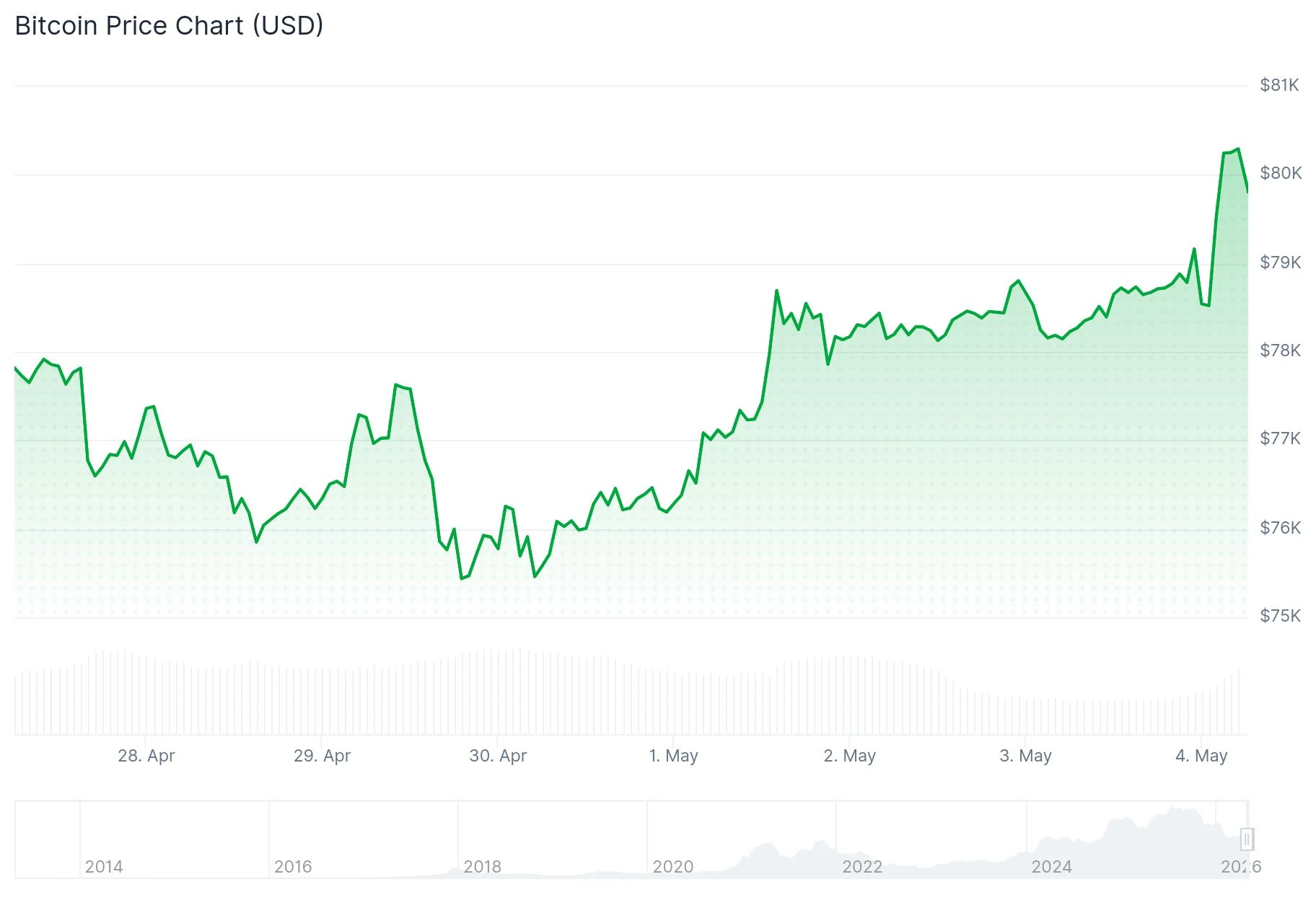
Bitcoin pushed through the $80,000 price level on Sunday, marking its first appearance at this threshold since January. The rapid ascent caught a significant portion of the market positioned in the opposite direction.
Data from Bitcoin.com News indicates that $150 million worth of cryptocurrency short positions faced forced closure during a concentrated 60-minute timeframe. Market data revealed that 62.8% of active Binance futures contracts were positioned short at the moment of the price movement.
Funding rates had already shifted into negative territory at -0.0051%, creating a situation where traders holding short positions were making daily payments to those holding long positions simply to maintain their exposure. These traders were essentially paying a premium to hold positions that would ultimately result in liquidation.
Anton Palovaara, founder at Leverage.Trading, provided clear analysis of the situation: “62% of Binance futures traders were short, and funding was negative. The market was literally paying them to hold the position. Bitcoin broke $80,000 and liquidated $150 million of them anyway. The issue was not direction. They ran out of margin before the move resolved. Being paid to hold does not mean you survive it.”
This point carries significant weight. Traders holding spot positions can maintain their holdings through periods of unrealized losses and wait for market recovery. Futures traders face automatic position closure when their margin reaches zero — exchanges execute liquidations immediately, resulting in complete loss of the position balance.
Derivatives Activity Amplified Price Action
Call option contracts showed heavy concentration at the $82,000 strike price leading into the market move. When gamma exposure accumulates at specific price levels, market makers hedging their exposure create selling pressure during upward moves, establishing resistance zones precisely where bullish momentum requires breakthrough.
The combination of forced short covering and concentrated options positioning created reinforcing dynamics that propelled the price beyond $80,000.
While price action shows strength, underlying market fundamentals present a contrasting narrative. CoinDesk, referencing CryptoQuant analytics, notes that spot market demand continues showing signs of weakness.
Institutional Flows Diverge From Spot Activity
Approximately $2.7 billion in exchange-traded fund inflows accumulated over a three-week period has failed to generate corresponding support in spot markets. The current rally derives its momentum from leveraged positioning and institutional ETF activity rather than direct purchasing in spot markets.
Polymarket odds currently assign a 56% probability to Bitcoin reaching $85,000 during the present month, with odds dropping to 23% for a $90,000 target.
The $82,000 price level contains the highest density of call option contracts, where market maker hedging activity introduces selling pressure at the precise threshold momentum needs to overcome.
Current market conditions show Bitcoin trading above $80,000, with prior Binance futures positioning at 62.8% short before the squeeze began, $150 million in liquidated positions, and spot demand indicators remaining subdued.