
Key Takeaways
- ETH currently trades at $2,160.46, showing a 1.95% decline during today’s session
- The asset maintains position above the 50-day moving average of $2,100.87 while remaining distant from the 200-day at $3,204.32
- BlackRock introduced its staked ETH ETF (ETHB) in March, enhancing institutional accessibility
- Ethereum spot ETFs attracted approximately $385 million in net capital during a six-day March period
- Open interest in ETH derivatives climbed roughly 8–9% within 24 hours, surpassing the $30 billion threshold
Ethereum currently sits at $2,160.46 after declining $43.01 during the trading day, representing a 1.95% decrease. The session began at $2,203.46, with price action ranging between $2,143.22 and $2,233.69 throughout the day.
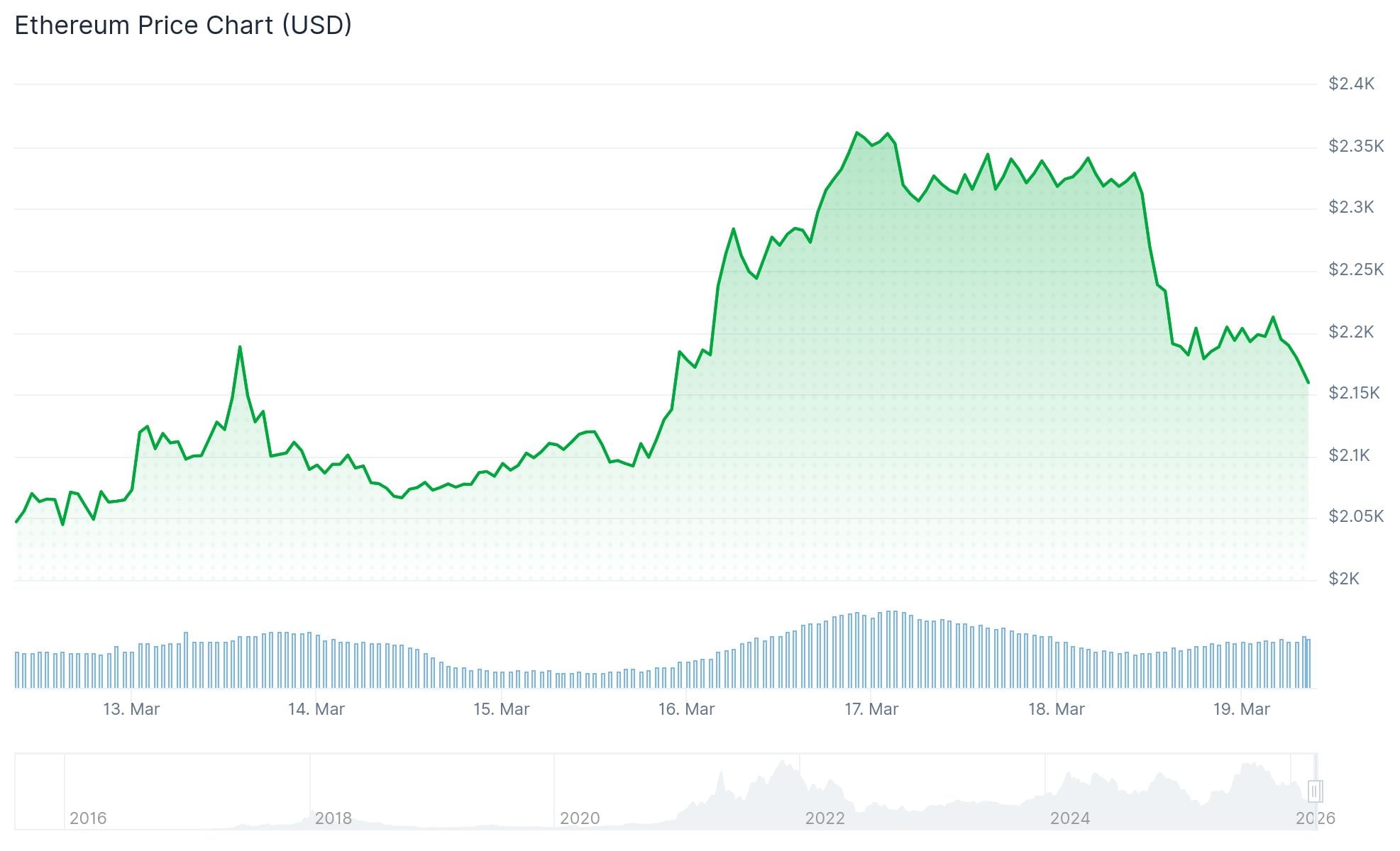
This pullback arrives after several weeks of upward momentum from the $2,000 zone. Despite today’s retreat, ETH maintains approximately 8–10% gains from early-month price levels. Trading volume registers around 71 million dollars, well below the typical 343 million dollar average, suggesting standard profit-taking activity rather than widespread liquidation.
Institutional Capital Flow Through ETF Vehicles
March brought a significant development with BlackRock’s launch of the iShares Staked Ethereum Trust (ETHB) on Nasdaq. This fund differs from previous spot ETH offerings by incorporating staking rewards directly into the investment vehicle, appealing to institutions seeking both price exposure and yield generation from Ethereum holdings.
Ethereum spot ETFs have demonstrated consistent capital attraction. Individual sessions have recorded figures such as 12.6 million dollars in net additions, with certain products capturing over 10 million dollars alone. Throughout a six-day window in March, approximately 385 million dollars entered ETH-focused funds collectively.
These capital movements have provided price stability during moments when speculative traders reduced positions.
Chart Structure and Price Zones
Daily chart analysis shows ETH maintaining ground above its 50-day moving average positioned at $2,100.87. This technical level has acted as a floor during recent retracements.
The 200-day moving average remains considerably higher at $3,204.32, indicating the extended-term trend has yet to fully reverse course.
Critical support establishes itself at $2,000–$2,060. A breach of that zone would bring $1,800 into focus as the boundary defining the current range’s lower extreme. Regarding overhead barriers, resistance concentrates at $2,235–$2,380, with a significant breakout threshold positioned near $2,500.
Ethereum open interest experienced an 8–9% expansion within a 24-hour window recently, exceeding $30 billion across primary exchanges including Binance, Bybit, and OKX. Derivatives market observers highlight that expanding open interest accompanying price appreciation can intensify movement velocity in either direction.
ETH faces difficulty establishing persistent trading above the $2,300–$2,400 corridor. The present formation reflects consolidation, characterized by overlapping candlestick patterns and subdued realized volatility that typically precedes larger directional shifts.
Ethereum’s total market capitalization hovers near $260.76 billion, securing its position as the second-largest cryptocurrency by valuation.